
Publishing STX B+ Tree 0.9 - Speed Gains over 0.8.6
Posted on 2013-05-07 21:16 by Timo Bingmann at Permlink with 0 Comments. Tags: #stx-btree
This blog post announces the new version 0.9 of my popular STX B+ Tree library of C++ templates, speedtests and demos. Since the last release in 2011, many patches and new ideas have accumulated. Here a summary of the most prominent changes:
- Changed the
find_lower()function, which is central to finding keys or insertion points to not use binary search for small node sizes. The reasoning behind this change is discussed in another blog post. - Added a
bulk_load()to allmapandsetvariants to construct a B+ tree from a pre-sorted iterator range. The sorted range is first copied into leaf nodes, over which then the B+ tree inner nodes are iteratively built. - The B+ tree template source code is now published under the Boost Software License! Use it!
- More minor changes are listed in the ChangeLog.
STX B+ tree version 0.9 is available from the usual project webpage.
The switch from binary search to linear scan, and all further patches and optimization call for a direct comparison of version 0.8.6 and 0.9. Because of special optimizations to the btree_set specializations, the following plots differentiate between set and maps.











")

 führt zur Definition von Differenzenmengen und beide Ergebnisse liefern elegante Konstruktionsverfahren für
führt zur Definition von Differenzenmengen und beide Ergebnisse liefern elegante Konstruktionsverfahren für 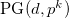 .
.